SIMD( Single Instruction Multiple Data ) 란 하나의 명령어로 여러개의 데이터를 처리할 수 있는 기술을 말한다.
CPU에서 지원되는 명령어 셋을 사용한다.
CPU의 아키텍처 모델에 따라 SIMD 기능을 지원한다.
- Intel & AMD
MMX, SSE, SSE2, AVX, AVX2, AVX512F - ARM
NEON
SIMD 를 이해하기 위해서는 기존에 알고있는 SISD( Single Instruction Single Data ) 와의 차이점을 알아야한다.
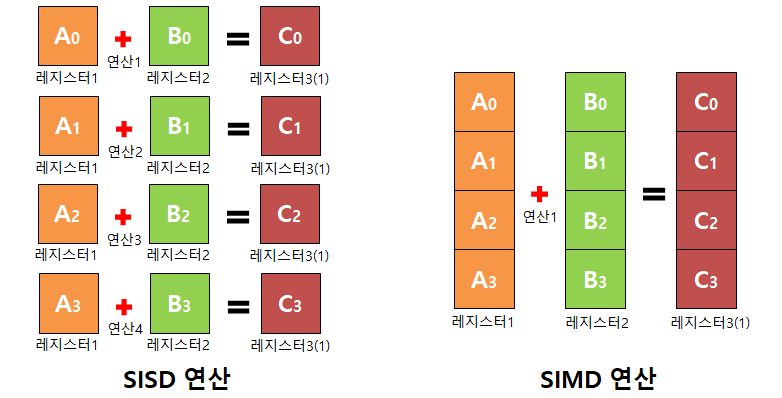
사진 출처 : 링크
4개의 32Bit 정수 A0, A1, A2, A3 가 있고, B0, B1, B2, B3가 있다고 했을 때
SISD 연산은 A0 + B0, A1 + B2, ... 각 각 덧셈을 하기 위해서 총 4번의 연산이 필요하다
SIMD 연산은 A0, A1, A2, A3와 B0, B1, B2, B3 를 각 각 묶어 1번의 연산만으로 연산한다.
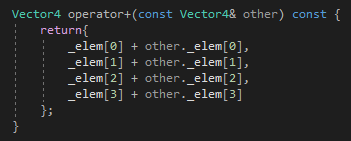
예를 들어, 우리가 Vector4 클래스를 만들고 이를 통해서 덧셈을 구현한다고 하자.
SISD 에서 덧셈은 다음과 같이 정의되어 있을 것이다.
이를 어셈블리어로 확인해 보자.
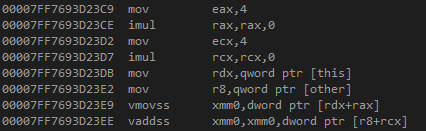
rax 레지스터와 rcx 레지스터를 0으로 초기화 한다.
this 와 other을 각각 rdx, r8 레지스터에 올린 후
각 각의 값에 접근해서 addss를 시도한다.
이를 총 4번 반복한다.
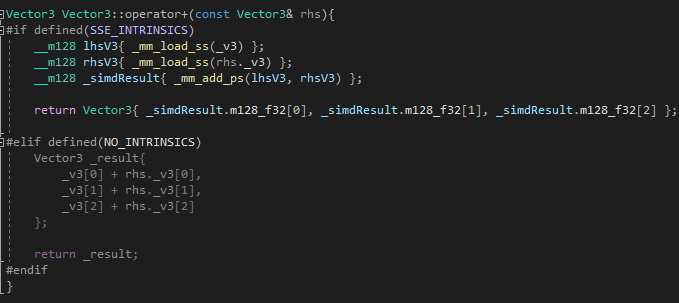
이를 SIMD 연산으로 수정해보자.

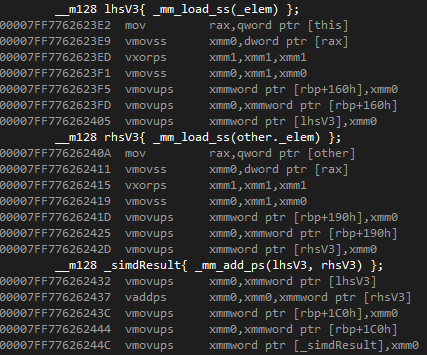
어셈블리를 몰라도 괜찮다.
위의 SISD 연산의 4배량보다 SIMD 연산량이 더 많은가?
동일하게 this와 other를 레지스터에 올리는 작업을 제외하여도 확연히 차이가 난다.
즉 위 예제와 같이 32비트 4개의 원소에 대해 덧셈 연산을 수행하는 add를 구현할때는 SIMD로 구현하는 것이 성능적으로 더 효율적이라는 것을 알 수 있다.
그래서 SIMD는 행렬 / 벡터 같은 연산에 주로 사용된다.
이제 각 SIMD Extension에 대한 레지스터 크기를 알아보자
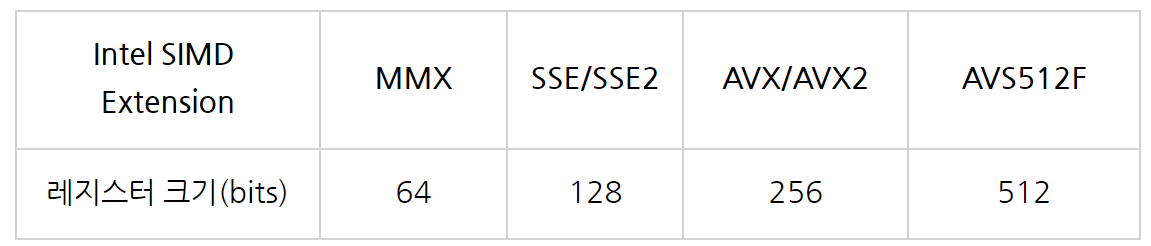
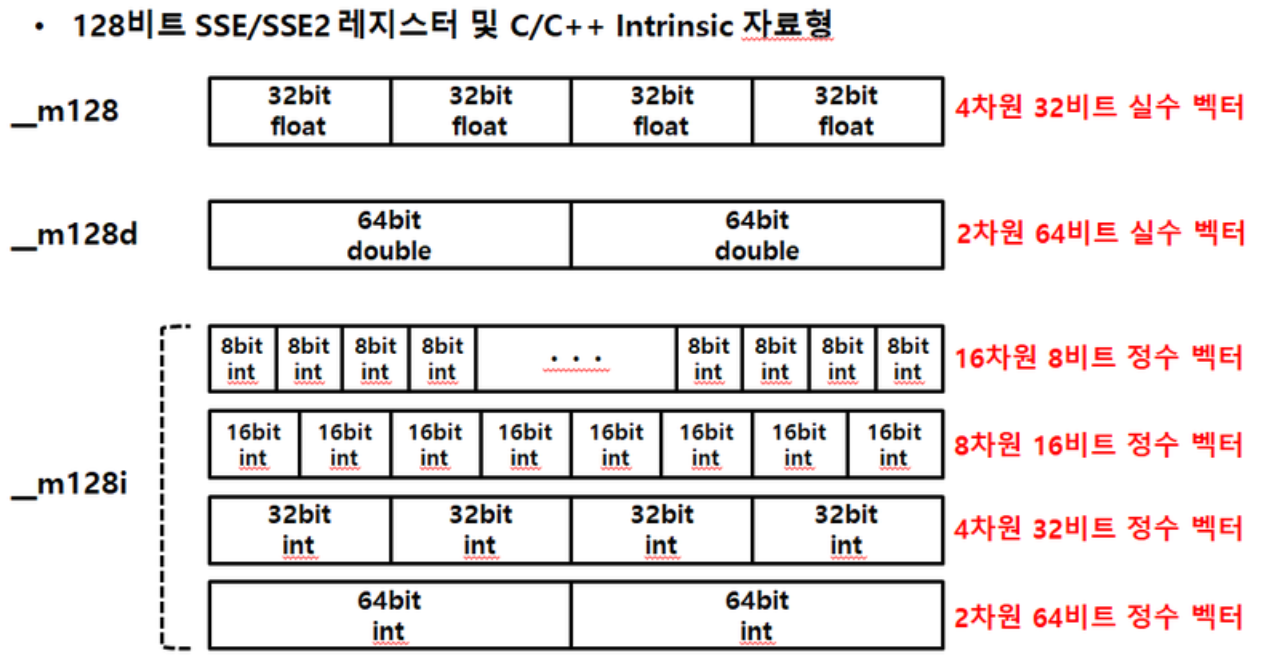
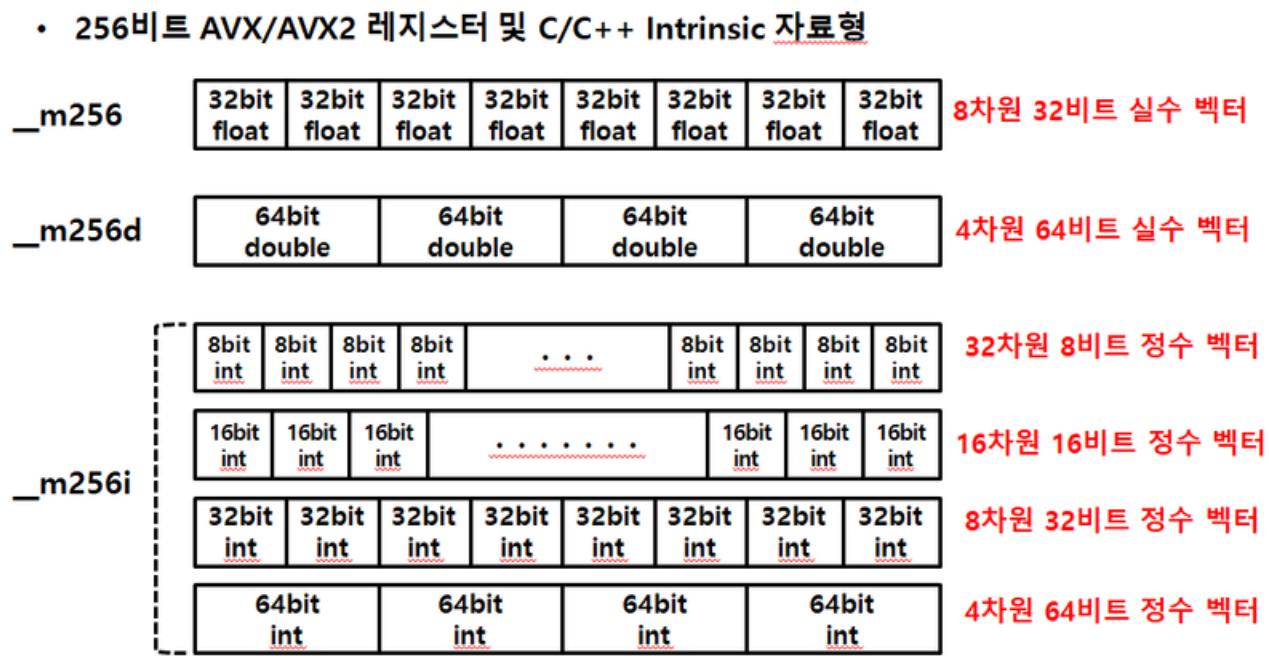
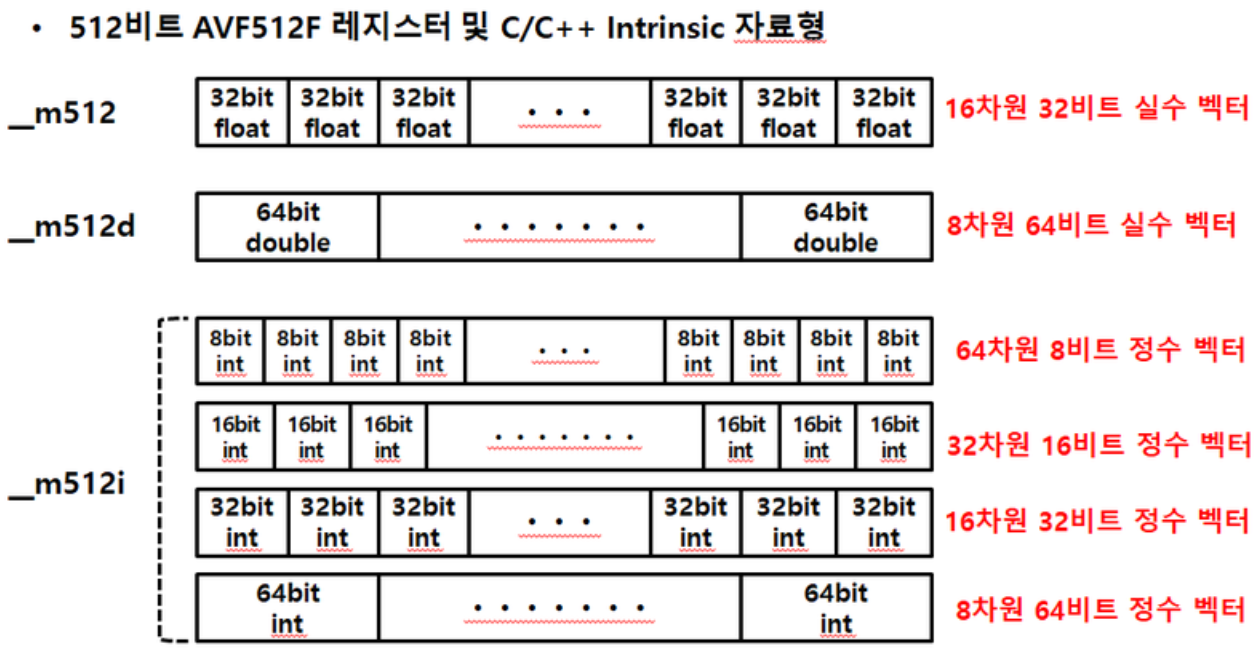
사진 출처 : 링크
(참고로, 16차원, 8차원 이렇게 적혀있는데 엄밀히 말하자면 1차원 배열일 뿐이다.. 1차원 16개 요소, 1차원 8개 요소..)
대중적으로, SIMD는 baseline simd, dispatcher simd 같은 식으로 개발이 많이 된다. 이를 설명하진 않는다. 검색해보자
현재 내가 사용하는 컴파일러가 어떠한 SIMD를 지원하는지 (옵션 유무 상관없이) 확인하는 방법은, 각 컴파일러마다의 정의된 전처리기를 확인해 보아야 한다.
필자같은 경우 MSVC에서 다음과 같이 사용하고 있다.
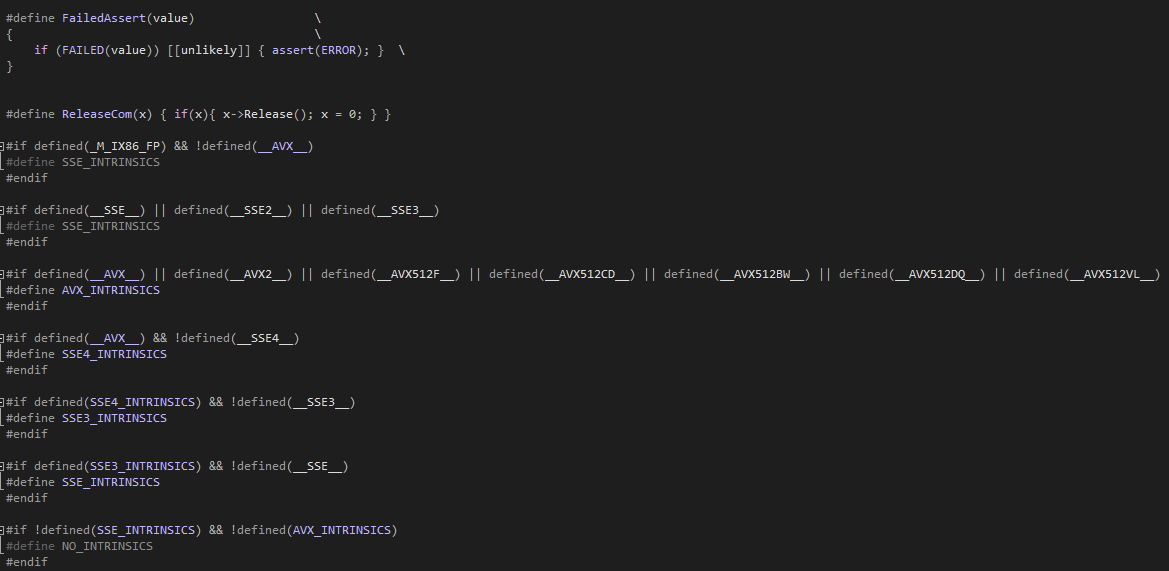
만약 SIMD 명령어 집합이 궁금하다면 다음 링크를 확인해보자.
https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html
Intel® Intrinsics Guide
Intel® Intrinsics Guide
www.intel.com
SIMD에 쓰이는 요소(변수)가 alignas 또는 align으로 정렬되어 있는 경우를 볼 수 있다.

이는 SIMD extension의 비트 수가 요구하는 사항을 충족하게 정렬시킨다.
메모리 시작지점을 align한 숫자의 배수로 맞추는것을 말하는데, 이를 함으로써 CPU는 정확한 주소에 정확히 16바이트를 가져와 16바이트 레지스터(16바이트 정렬된 _m128 자료구조)에 1:1 대응시키는 것이다.
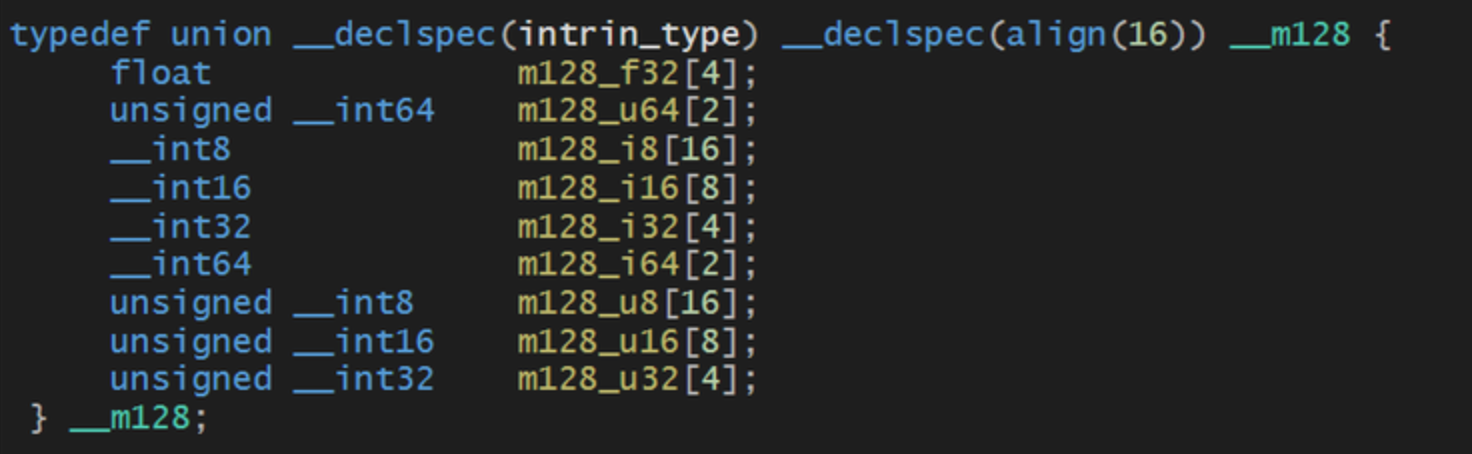
만약 256비트인 AVX 를 사용하게 되면 32바이트 정렬을 시켜야 한다.
만약 정렬하지 않으면 다음과 같은 문제중 하나가 발생한다.
- 비정상적인 메모리 접근을 인식하여 OS가 프로그램을 종료시킴
- CPU 혹은 컴파일러가 해당 데이터가 속한 두 메모리 영역에 접근한 뒤 적절한 비트 연산을 거쳐 원하는 값을 만들어줌
- 주소를 적당히 16바이트의 배수로 변경하여 메모리에 접근함
- 별 문제 없이 실행됨

즉 다음과 같이 ( 파란색 블럭 하나당 1바이트라고 간주) 정렬되어있지 않은 상태에서
A 를 읽고, B를 읽으려 할 때 메모리를 B의 시작 메모리가 떨어져 있기 때문에 비정상적인 메모리 접근으로 인식
벡터 & 행렬과 같은 연산에서 4개의 데이터를 패킹하여 한 번의 연산만으로 연산을 끝낼 수 있다는건 충분히 좋은 점이나, 오늘날 대부분의 컴파일러와 최신 CPU들은 SIMD 연산을 알아서 사용하여 코드를 최적화 해준다.
UE4 의 Vector4가 SIMD없이 Scalar만으로 구현된 것도(Matrix는 SIMD임) 이 때문인데
SIMD 같은 경우는 load_ps_ss 같은 연산때문에 데이터를 저장하는 문제가 있으나 컴파일러가 지원하는 SIMD는 저장 연산이 없기 때문에 더 빠르게 작동한다.
추가적으로 이미 align된 데이터를 load_ps_ss 같은 걸 사용하여 __m128로 옮길 필요가 없다. 이는 align되지 않은 데이터를 align된 데이터로 바꾸어주는 역할을 할 뿐이다.
즉, 이미 원소가 16바이트로 정렬되어 있다면
__m128 *_lhsV3 {reinterpret_cast<__m128*>(&data)};와 같이 변경하여 사용하면 된다.
'C++ > Before' 카테고리의 다른 글
| 컨테이너 상속에 대한 (0) | 2019.02.22 |
|---|
